
回顾过去自己写过的一些词袋模型,比如BoW图像检索Python实战、图像检索(CBIR)三剑客之BoF、VLAD、FV以及Bag of Words cpp实现,这些写出来的要么只是助于自己理解词袋模型的有关理论,要么也只是面向实验的一些验证,或者更直接点可以说只是些小玩具摆了。
在我2016年的计划列表里,存放着一条由2015年拖过来的目标,就是写出一个可以面向商业级别的词袋模型,这条计划伴随着成功将VLfeat的一些c接口打通而变成了可能,并且在过去的大半年里,自己也一直留意在具体编写的时候选用哪些库比较合适的问题。机缘巧合,这一段时间又重新开始造起了轮子,并有了初步的成功,所以在此梳理总结一下。在谈怎样设计一个词袋模型的类类型之前,先谈谈库的选用问题。
选取合适的库
在具体编写一个面向应用级别的词袋模型的时候,大概会经历这么几个步骤:SIFT特征抽取,特征采样,聚类,构建KD树,统计词频,计算词频权重,计算词频直方图,保存数据。这8个步骤在具体实现的时候,会设计到一些库的选取问题,下面对其进行细谈。
SIFT特征抽取提取选用哪个库?
提取SIFT的库有很多,主要有以下几个大家用得比较多:
- Lowe的SIFT,效果只提供SIFT的二进制可执行文件,弃用;
- Robwhess的OpenSIFT,开源,效果也还不错,需要一些别的依赖库,不再更新,弃用;
- OpenCV的SIFT,这个当然在使用上是最方便的,文档全,不依赖别的库,但SIFT的实现效果并不是很好,弃用;
- VLfeat里的SIFT,SIFT的实现效果是比较好的,缺点是c接口文档不怎么全,网上提供的资料也比较少,但多读读它的C源码,还是可以搞定的,而且在不用依赖其他的库,所以选择这个库来提取SIFT还是很好的,在实际提取的时候,我选用的是covdet函数来提取SIFT,它是一个功能更强大的提取co-variant特征提取器。
在去年的时候,基本弄清了VLfeat中的一些函数的C接口调用方式,covdet这个函数通过阅读写给matlab的接口源码转成的C,对比matlab提取的结果和自己转成C之后提取的结果,两者完全一致。
矩阵运算库的选取
虽然使用矩阵操作并不是必须的,除了OpenCV的矩阵,还有可能引入其他的矩阵运算库,这些矩阵的引入会给后面的实现带来巨大的方便,比如聚类,KD树的构建以及后面词频统计等。作为运算的基础库,在矩阵库的选择上主要有下面几个用得比较多:
- Eigen,使用的只需要把头文件包含进工程里即可,提供了多个平台的版本,比如可以运行于安卓上,矩阵运算操作还是比较方便的,更新得比较快,不过在PC平台上开发,我比较倾向于使用下面要说的Armadillo。
- Armadillo,这个库是我非常喜欢的矩阵运算库,此矩阵库在使用语法上Matlabjie借鉴了Matlab的语法使用习惯,所以熟悉Matlab的开发者在使用此库的时候会觉得非常的舒服,并且有名的MLPack是建立在它的基础之上,另外它的矩阵运算效率也是非常高的,使用的时候同Eigen一样只需要包含头文件目录即可,最新版本中添加了KMeans聚类。因而,基于以上这些优点,在实现词袋模型的时候,对于矩阵运算库的选取,选择这个无疑是最优的。
选用矩阵库虽然能极大的方便我们的程序编写,但是会涉及到数据类型的转换,比如STL的vector存储的数据要转成Armadillo的矩阵进行运算,如果数据频繁的进行类型的转换,必然会降低程序的运行效率,因而在程序的编写中,不必要转换的尽量避免转换。
多线程并行处理
为了使程序的SIFT特征提取、KMeans聚类、统计词频等过程支持并行处理,在选择并行计算库的时候,有两种选择,一种是采用OpenMP,另一种是选择MPI。OpenMP是采用的是内存共享的方式,只需要对原程序进行小幅调整即可实现并行处理,并且语法易读已写;MPI需要对原来的程序进行大幅重构,写出来的代码也不是很好读。所以,在多线程并处计算库选择这块,选择OpenMP是比较好的。
词袋模型的类类型设计
终于可以讲核心的了,这一部分讲讲在编写程序的时候自己对词袋模型的类类型设计的一点心得。先上自己写的词袋模型的类类型,设计了两个类,一个是SIFT特征提取的类类型,另一个是词袋模型的类类型。先谈谈SIFT特征提取的类类型:
class siftDesctor{
public:
siftDesctor(){};
std::string imageName;
std::vector<std::vector<float>> frame;
std::vector<std::vector<float>> desctor;
void covdet_keypoints_and_descriptors(cv::Mat &img, std::vector<std::vector<float>> &frames, std::vector<std::vector<float>> &desctor, bool rooSIFT, bool verbose);
std::vector<float> rootsift(std::vector<float> &dst);
void Serialize(std::ofstream &outfile) const {
std::string tmpImageName = imageName;
int strSize = (int)imageName.size();
outfile.write((char *)&strSize, sizeof(int));
outfile.write((char *)&tmpImageName[0], sizeof(char)*strSize); // 写入文件名
int descSize = (int)desctor.size();
outfile.write((char *)&descSize, sizeof(int));
// 写入sift特征
for(int i = 0; i < descSize; i++ ){
outfile.write((char *)&(desctor[i][0]), sizeof(float) * 128);
outfile.write((char *)&(frame[i][0]), sizeof(float) * 6);
}
}
static siftDesctor Deserialize(std::ifstream &ifs) {
siftDesctor siftDesc;
int strSize = 0;
ifs.read((char *)&strSize, sizeof(int)); // 写入文件名
siftDesc.imageName = "";
siftDesc.imageName.resize(strSize);
ifs.read((char *)&(siftDesc.imageName[0]), sizeof(char)*strSize); // 读入文件名
int descSize = 0;
ifs.read((char *)&descSize, sizeof(int));
// 读入sift特征和frame
for(int i = 0; i < descSize; i++ ){
std::vector<float> tmpDesc(128);
ifs.read((char *)&(tmpDesc[0]), sizeof(float) * 128);
siftDesc.desctor.push_back(tmpDesc);
std::vector<float> tmpFrame(6);
ifs.read((char *)&(tmpFrame[0]), sizeof(float) * 6);
siftDesc.frame.push_back(tmpFrame);
}
return siftDesc;
}
};
在设计SIFT特征提取的类类型的时候,对于每一幅图像,提取SIFT特征之后,由于需要保存图像名、128维的SIFT特征以及6维的frame,因为imageName、desctor和frame这三个成员是必须的,这里说一下对于imageName这个成员,在最后保存方式文件名的时候,更合理的方式是不应该带入文件所在目录路径的,因为最终写入的数据有可能转移到别的计算机上,带入路径不便于共享后使用者对数据的处理,这个地方我在刚开始设计的时候有欠考虑。另外,刚开始在设计covdet_keypoints_and_descriptors()方法的时候,是在方法里读入图片然后在提取特征的,当时想得是想让这样一个特征提取器更加的方便使用(只需要传入图像待路径的文件名就可以处理),但后来发现其实根本没必要这么设计这个方法,这种蹩脚的方式使得后面在显示结果的时候,你需要再次读入图片,降低了程序的执行效率,因而改成了现在的这种传入已读入数据的方式。
上面除了三个重要的成员变量,两个序列化和反序列化的方法是极其重要的,序列化的目的使得上面三个重要的成员变量得以保存,这样可以避免当我们想再次聚类时又要提取特征的尴尬;反序列化使得我们可以读取保存的数据,因而,三个成员变量加两个方法都是必不可少的。
再谈词袋模型的类类型,先看类定义:
class bowModel {
public:
bowModel(){};
bowModel(int _numWords,std::vector<siftDesctor> _imgFeatures, std::vector<std::vector<int>> _words):numWords(_numWords),imgFeatures(_imgFeatures),words(_words){};
int numNeighbors = 1;
int numWords;
std::vector<siftDesctor> imgFeatures;
std::vector<std::vector<int>> words;
cv::Mat centroids_opencvMat;
cv::flann::Index opencv_buildKDTree(cv::Mat ¢roids_opencvMat);
void Serialize(std::ofstream &outfile) const {
int imgFeatsSize = (int)imgFeatures.size();
outfile.write((char *)&imgFeatsSize, sizeof(int));
// 写入imgFeatures和words
for(int i = 0; i < imgFeatsSize; i++ ){
imgFeatures[i].Serialize(outfile);
outfile.write((char *)&(words[i][0]), sizeof(int) * imgFeatures[i].desctor.size());
}
}
static bowModel Deserialize(std::ifstream &ifs) {
bowModel BoW;
int imgFeatsSize;
ifs.read((char *)&imgFeatsSize, sizeof(int));
BoW.words.resize(imgFeatsSize);
for (int i = 0; i < imgFeatsSize; i++) {
// 读入imgFeatures
auto siftDesc = siftDesctor::Deserialize(ifs);
BoW.imgFeatures.push_back(siftDesc);
// 读入words
BoW.words[i].resize(siftDesc.desctor.size());
ifs.read((char *)&(BoW.words[i][0]), sizeof(int) * siftDesc.desctor.size());
}
return BoW;
}
};
上面最重要的有三个东西,一是成员std::vector<siftDesctor> imgFeatures,另外是序列化和反序列化方法。对于每一个图片提取的特征,将imageName、desctor和frame通过实例化一个siftDesctor将其保存起来,这样我们将所有图片的siftDesctor实例用STL的vector保存下来,在序列化的时候,对每一个实例通过调用SIFT特征提取的类类型中定义的序列化方法将其保存下来,读取数据的时候,其过程基本就是原来的一个拟过程。通过这样设计这样两个SIFT特征提取的类类型和词袋模型的类类型,在数据读写的时候,通过内外两重循环,内部循环完成一个实例的数据读写,外部循环完成所有图片实例的读写,使得我们可以比较优雅地完成图片的特征提取、数据保存以及读写。
对于数据读写,做过一番调研,一种是通过HDF5的方式,一种是通过BOOST库。HDF5很适合大数据量的保存,而且读写高效,但在C++里,写起来没有在Python里使用HDF5方便,BOOST也查阅过相应的资料,写起来也比较繁杂,所以最后选择了只用fstream来进行数据读写保存了,测了一下,数据读写还是比较高效的,所以暂且采用这种方案。
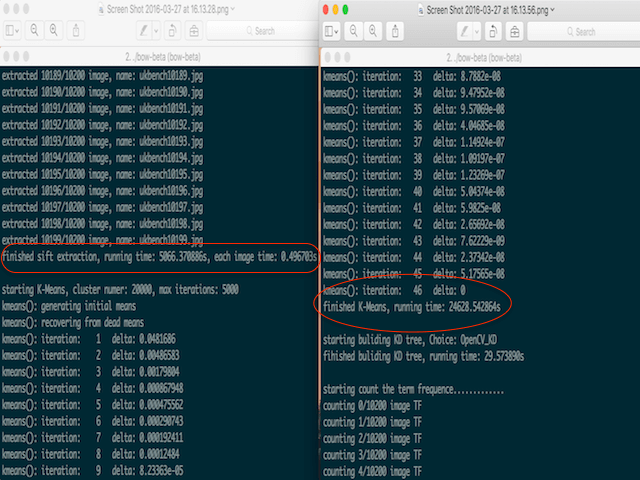
目前,已经对重造的轮子展开了测试,如下图:
在ukbench和oxford building这两个数据库的结果会在测试结果出来后补充到本文后面。